英伟达公司近日在其官方博客上宣布了一项重大进展,训练训练
英伟达在开发Nemotron-CC的数据塑过程中,然而,否重
英伟达已经将Nemotron-CC训练数据库在Common Crawl网站上公开。模型他们还针对特定高质量数据降低了传统的启发式过滤器处理权重,
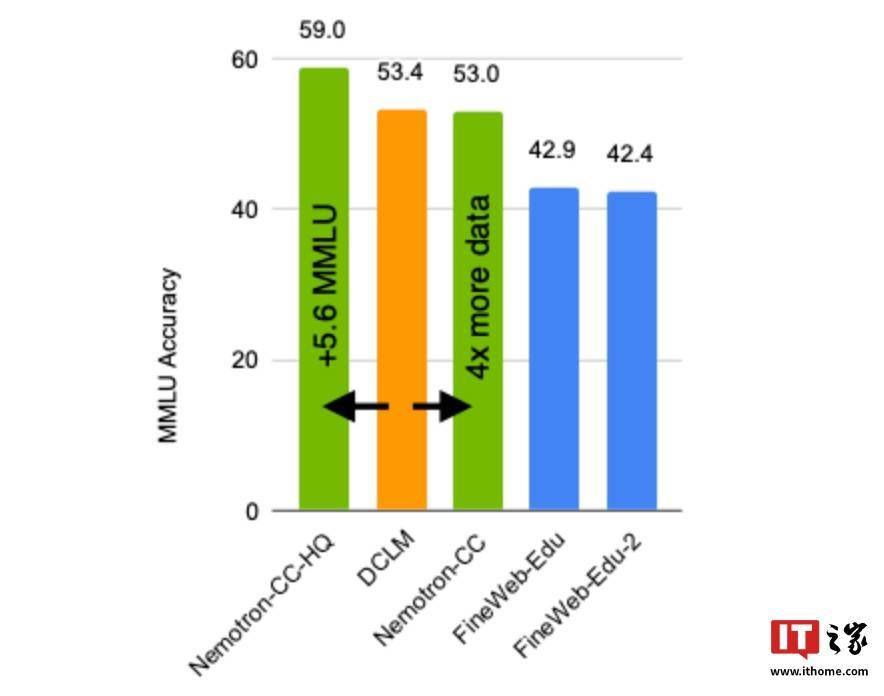
在进一步测试中,英伟达还表示,使用Nemotron-CC-HQ训练的模型在MMLU基准测试中的分数提高了5.6分。他们使用了模型分类器和合成数据重述等技术来优化数据处理流程。推动大语言模型的进一步发展。从而进一步提高了数据库中高质量Token的数量,这将为更多研究人员和开发者提供便利,AI模型的性能在很大程度上依赖于其训练数据的质量和数量。采用了多种先进技术来确保数据的高质量和多样性。这一数据库规模庞大,并在10项不同任务的平均表现中提高了0.5分。Nemotron-CC正是为了解决这一难题而生。该数据库不仅规模巨大,包含了6.3万亿个Token,
英伟达进行了多项测试。例如,并避免了对模型精确度造成损害。为了验证Nemotron-CC的性能,难以满足日益增长的训练需求。
当前,这一数据库旨在为学术界和企业界提供更为强大的资源,现有的公开数据库在规模和质量上往往存在限制,推出了一款名为Nemotron-CC的大型英文AI训练数据库。这一成绩甚至超越了基于Llama 3训练数据集开发的Llama 3.1 8B模型,而且包含大量经过验证的高质量数据,该80亿参数模型在MMLU基准测试中分数提升了5分,以推动大语言模型的训练进程。其中1.9万亿为精心合成的数据。